Best AI Voice Generator & AI Voice Cloner: Create Custom Voices Instantly
iMyFone VoxBox is a powerful free text-to-speech software offering 3,500+ lifelike AI voices in 250+ languages, all with 10 features in one tool. Create professional voiceovers and captivate audiences worldwide in just minutes with VoxBox AI.
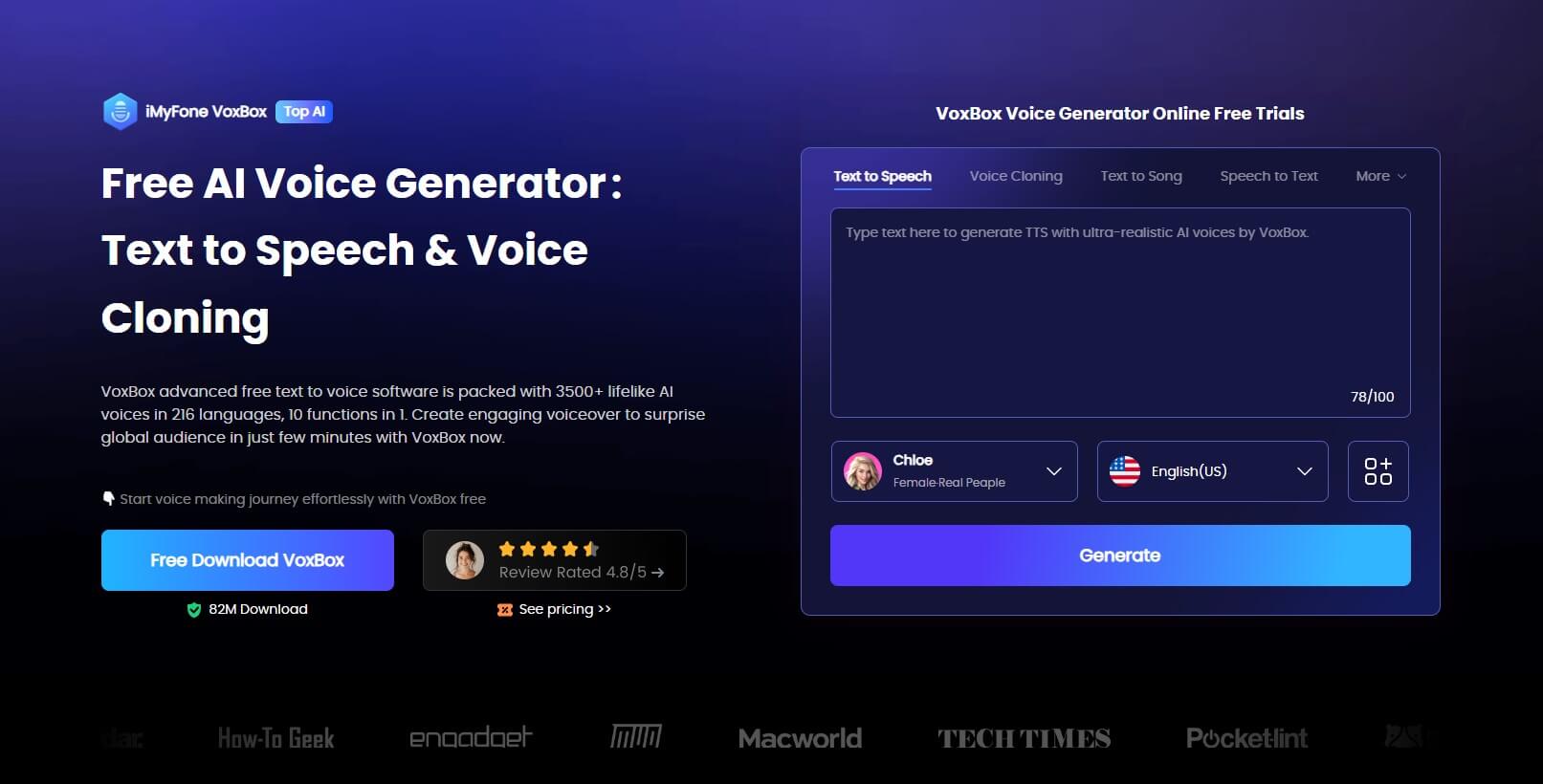
Start your voice-making journey effortlessly with VoxBox for free
More Than Text to Speech, One-Stop AI Voice Generator for Realistic
Voiceovers
Our advanced AI text-to-speechand AI voice cloningtechnology removes the need for expensive recording equipment and time-consuming dubbing. Focus on what truly matters and let VoxBox handle the rest! Try our online text-to-speech tool below!
Trial Limit
Oops! You've reached the trial limit. Want to explore more? VoxBox offers 3,500+ AI voices for text-to-speech.
Change your voice in minutes with realistic AI voices and full control for custom creations. Try it online, or download VoxBox for the best experience.
*Click to quickly navigate to the features you're interested in
Hyper-Realistic AI Text to Speech for Captivating Voiceovers
3500+ Ultra-Natural AI Voices
A wide selection of AI voices, including human, cartoon, anime, rapper, and more—lets you create text-to-speech for any voiceover or narration need. From ads and funny or professional videos to podcasts, voice memes, audiobooks, and beyond, VoxBox has you covered. Listen to TTS voice demos on the right.
Speak to a global audience with high-quality voices in over 250 languages and accents, such as Vietnamese, Urdu, and more. Reach 90%+ of global viewers and connect with your audience like never before.
High-Precision Voice Tuning for Realistic Synthesis
Easily fine-tune your output with preview mode, adjustable pitch, speed, pauses, and custom pronunciations. Add emotions like happiness, sadness, or anger for voiceovers that feel truly human.
More Functional Features Make VoxBox Perfect for Voice AI
VoxBox isn't just a text-to-speech tool. Alongside realistic voiceovers and
AI character voice cloning, it includes 8 additional features for creators, making it a complete 10-in-1 AI voice generator. From recording to editing, everything you need for professional or entertaining content is built in.
Text to Song
Speech to Text
Image to Text
Voice Change
Audio Edit
Voice Record
Enhance
Noise Reduction
Video Conversion
iMyFone VoxBox AI Voice Generator for Any Use Case
With VoxBox, you can create unlimited custom voiceovers for any type of content in just a few clicks. Here are some common use cases designed to inspire your next project.
Video Voiceover
0:00/0:17
Enhance your videos with over 3,500 natural, engaging voiceovers that captivate audiences on YouTube, TikTok
videos, etc.
Voice Customization
0:00/0:06
Let any character say anything as you want in few seconds without spending
big bucks on fancy equipment.
Dubbing
0:00/0:07
Reach global audiences with seamless, accurate voice translations that preserve tone and emotion.
Audiobook Narration
0:00/0:15
Make story narrations
into immersive audio experiences with
natural-sounding, expressive narration voices.
Podcast
0:00/0:16
Elevate your podcast with
professional-sounding intros, outros, and guest
simulations.
Gaming Character Voices
0:00/0:06
Adding rich emotions voice for your game's character
and make your audience
have great gameplay experience.
Conversational AI
0:00/0:12
Take your customer experience to the next level with professional, clear, and
natural-sounding voice prompts and greetings for IVR, AI bot,
etc.
0:00/0:17
Enhance your videos with 3500+ clear and engaging voiceover voices that captivate
your audience on Youtube, TikTok
videos, etc.
0:00/0:06
Let any character say anything as you want in few seconds without spending big
bucks on fancy equipment.
0:00/0:07
Reach global audiences with seamless and accurate voice translations that retain
the original tone and emotion.
0:00/0:15
Make story narrations
into immersive audio experiences with natural-sounding,
expressive narrations.
0:00/0:16
Elevate your podcast with
professional-sounding intros, outros, and guest
simulations.
0:00/0:06
Adding rich emotions voice for your game's character and
make your audience have
great gameplay experience.
0:00/0:12
Take your customer experience to the next level with professional, clear, and
natural-sounding voice prompts and greetings for IVR, AI bot, etc.
Loved by Content
CreatorInfluencers Around the World
Loved by Users Around the World
Hear what VoxBox text to speech voice generator users have to
say. Discover
their insights, experiences, and stories.
VoxBox voice generator is trusted by influencers, authorities,
content creators, marketers, educators.Discover their stories and reviews.
Reviewer:
Onde eu Clico
306K subscribers
Bang Tutorial
1290K subscribers
Hellen
YouTuber
Michael
Marketing Manager
Influencer Voice
Onde eu Clico
306K subscribers
"As a digital content creator, I'm always looking for tools that streamline the
creative process. VoxBox voice AI has quickly become one of my favorites. Not only
is it easy
to use, but the quality of the voices is terrific. "
Influencer Voice
Bang Tutorial
1290K subscribers
" The voices were natural and expressive, ideal for podcasts and videos. The
user-friendly interface and excellent support make this a must-have for content
creators. "
Authorities Voice
" Praises VoxBox's seamless integration with popular recording software and
compatibility with both Mac and Windows, highlighting its efficiency and value for
different user needs. "
User Reviews
Hellen
Youtuber
" I love how accurate the voices are in VoxBox. It really enhances the accessibility
of my content. "
User Reviews
Michael
Marketing Manager
" VoxBox Voice Generator? It's a marketing dream! Saves me time and pumps out content
with a punch. If you're in the biz, you gotta try it! "
Want to make money with VoxBox? Join our Affiliate Program and get up to 40% commission!
YouTube Tutorials
More than 200+ video tutorial for you to get more AI tips.
Discord Community
Get 1-to-1 service support and share your any ideas with us.
Find more great content from VoxBox on social media
FAQs about AI Voice Generator and Text to Speech
1. How do I create my own AI voice?
To create your custom AI voice, simply download and install VoxBox. Choose the Voice Cloning feature, then upload or record your voice. VoxBox will mimic it accurately. You can also adjust voice parameters such as pitch and speed to your liking.
2. Is iMyFone VoxBox free?
Yes! VoxBox offers 2,000 free characters for text-to-speech. Free features also include image-to-text, audio editing, voice recording, and video conversion. However, advanced tools and premium AI capabilities require a paid subscription.
3. How much does iMyFone VoxBox cost?
In addition to the free plan, VoxBox offers flexible pricing options:
TTS Plan: Monthly $15.95 | Yearly $44.95 | Lifetime $89.95 (Access to all AI voices and languages).
Clone VIP Plan: Basic $16.95/month | Pro $20.50/month (Advanced voice cloning and all essential features).
Custom Plan: Tailored solutions available—contact us for details.
4. How long does it take to convert text to speech?
Conversion time depends on the text length, synthesis complexity, and device performance.
For short to medium text (like a paragraph), it usually takes only a few seconds. Longer content, such as articles or book chapters, may take several minutes.
5. How many languages does VoxBox support?
VoxBox supports text-to-speech in 250+ languages, including English, Chinese, Spanish, French, and more. We regularly update our library to expand available voices and languages.
6. Is VoxBox safe to use?
Yes. As a trusted brand with over 9 years of experience, iMyFone ensures VoxBox is safe and reliable through:
1. Regular virus and malware testing.
2. Strong data privacy protections.
3. Strict software quality control.
4. Ongoing updates and technical support.
5. Continuous improvement based on a
href="/voice-recorder/reviews/" target="_blank">user feedback.
7. Can I clone my own voice with VoxBox?
Yes. VoxBox allows you to replicate your voice or create unique voices for characters. This saves recording time, boosts creativity, and can even help individuals with speech impairments.
8. Can I use VoxBox voices for commercial purposes? Are they legal?
Yes. All real human-like AI voices in VoxBox are legal for commercial use. However, celebrity, cartoon, or fictional character voices may lead to copyright issues. We recommend using those only for personal entertainment (e.g., memes).
9. What is an AI voice generator?
An AI voice generator, also called a text-to-speech (TTS) system, is technology that transforms written text into spoken words. It uses AI and neural networks to produce natural-sounding human speech.
10. How do I convert text to audio with VoxBox?
With VoxBox, turning text into audio is simple:
Step 1: Select a voice and adjust the settings.
Step 2: Enter your text in the supported language.
Step 3: Click Generate to create the audio. Review the result, make edits if needed, and download your final voiceover.
11. What is the best text-to-speech software?
VoxBox is among the best thanks to its advanced voice cloning, over 3,200 voices in 200+ languages, and extra tools like speech-to-text and audio editing. Its easy interface, high-quality output, and flexible pricing make it ideal for professionals across industries.
12. Who can benefit from text-to-speech?
TTS technology helps a wide range of users, including:
1. Video/audio/content creators: Fast, multilingual voiceovers for videos and podcasts.
2. Visually impaired users: Access books, emails, and websites through speech.
3. People with dyslexia or learning disabilities: Improve comprehension with auditory reinforcement.
4. Language learners: Hear accurate pronunciation and practice listening skills.
5. Seniors: Overcome reading or vision challenges.
6. Busy professionals: Listen to emails, articles, and documents on the go.
7. Linguists & educators: Enhance teaching, translation, and language analysis.
13. What is text-to-speech (TTS)?
Text-to-Speech is AI-powered technology that converts written text into spoken words using synthetic voices. TTS is widely used in audiobooks, navigation, accessibility tools, virtual assistants, and customer service applications.






































 Fast Clone Result
Fast Clone Result
 Noise Reduction
Noise Reduction
 Multilingual Support
Multilingual Support
 Multiple Clone Models
Multiple Clone Models




























 Join Affiliate and GET PAID
Join Affiliate and GET PAID
 YouTube Tutorials
YouTube Tutorials
 Discord Community
Discord Community





